This post was inspired by some onboarding notes that Sana took to document our process. Thanks Sana!
This is a reference for some processes around the following:
GitHub Issues
We use GitHub issues to organize our tasks, whether big or small or unknown in scale.
Goals
A goal is nothing more than an issue that is meant to collect other sub-issues. In our case, we work in quarterly goals, but you can divide time however is most useful to you.
We like to attach a label, such as goal:primary, to such issues.
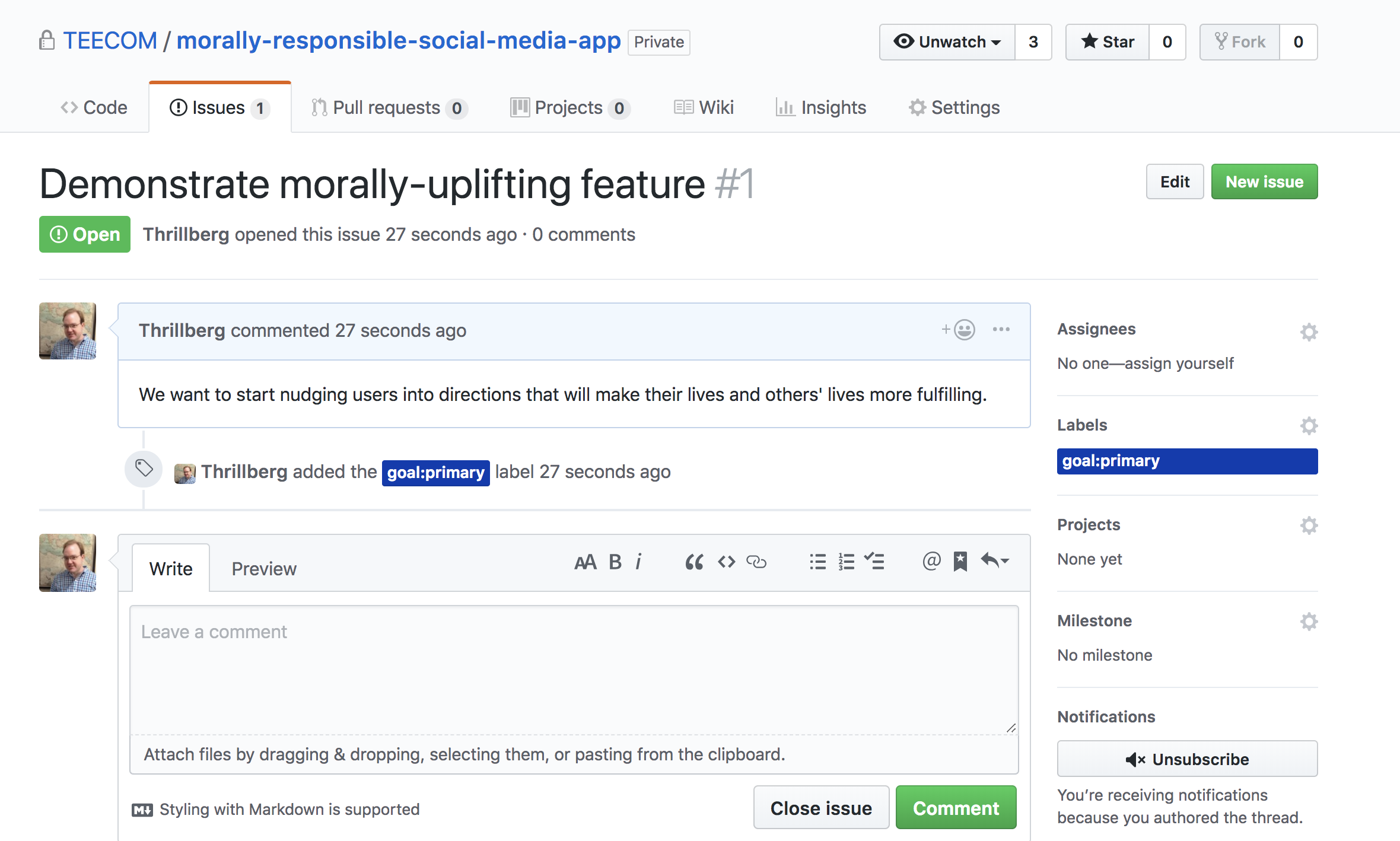
When we open issues that address the goal, we can tag the goal’s issue number (in this case, 1) in the smaller issue’s description. Just by writing “#1”, GitHub links the two.
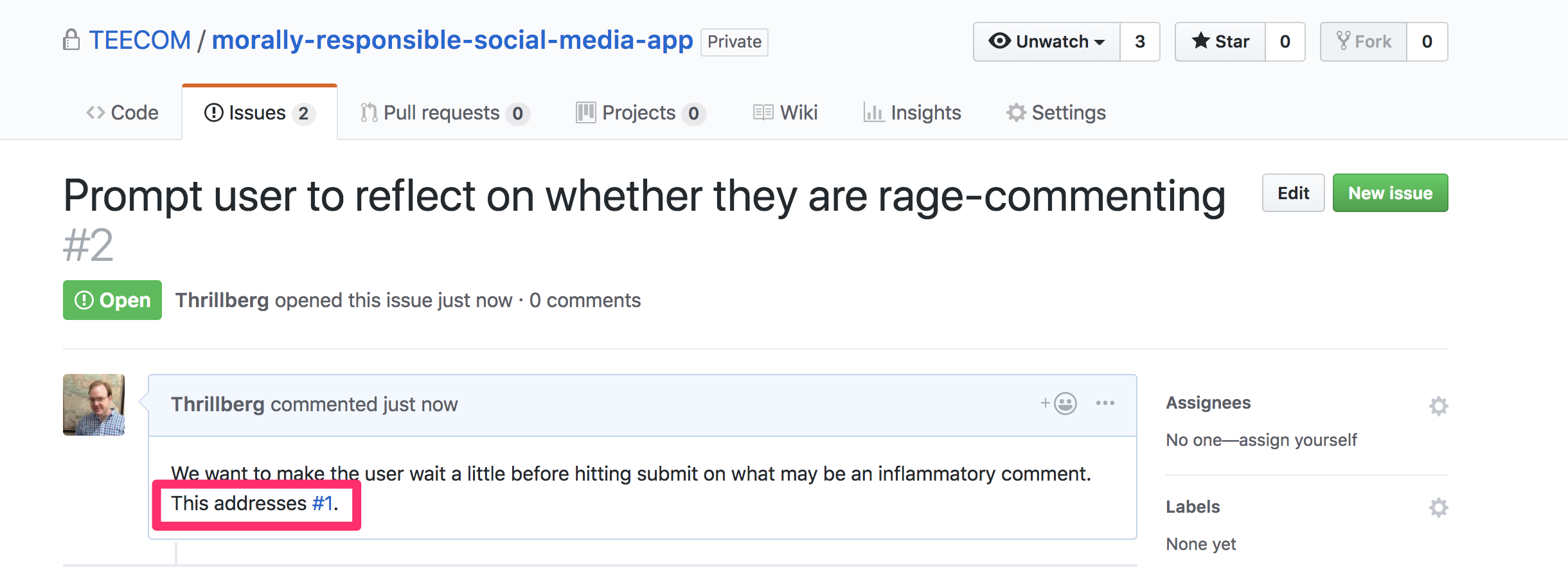
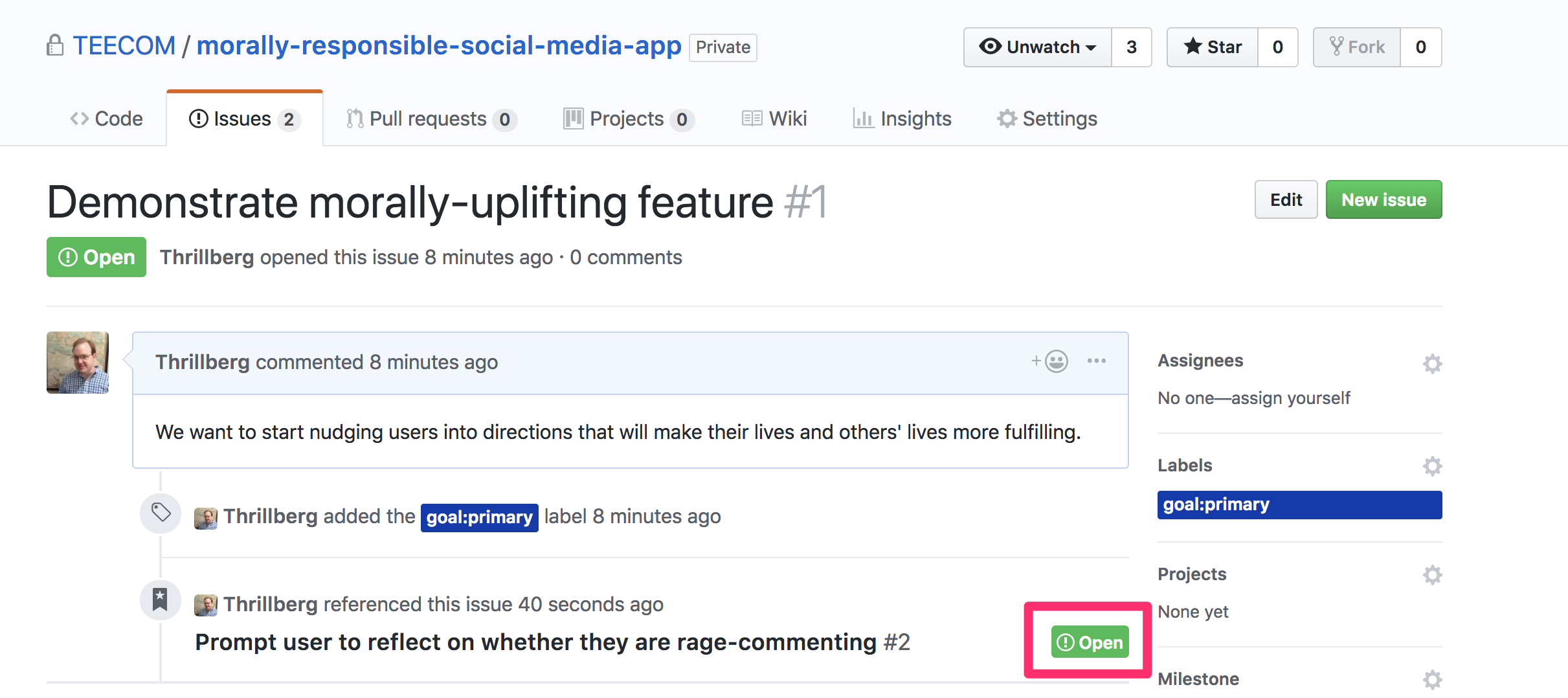
And now when we look back at the bigger goal-issue, we see a reference to the smaller issue! You can see that when the smaller issue is closed (by completion or otherwise), the green Open badge will become a red Closed badge. This turns this view into a checklist of sorts.
Milestones and milestone planning
In addition to the above, we use GitHub Milestones to plan out 2-week cycles, assigning each issue to a milestone as we determine we want to address it.
We have a milestone planning meeting every two weeks in which we (briefly) review the work of the prior two weeks. (This usually involves a fair amount of self-congratulation, which is very healthy when warranted.) The main activity of the planning session is to identify issues that we want to work on next. There should be a healthy mix of core issues related to goals (as described above) and other issues (including bugs!) that may not be categorized. We also assign issues to contributors. For this we’ve tended to assign one solo issue per contributor and a larger, more thought-provoking and decision-heavy issue for pairing on.
Git Workflow
The following commands make use of the aliases outlined below.
We name our branches in a generic way, preceding the issue number with fix-.
Therefore, if we want to work on getting users to pause before commenting, we
can work on branch fix-002:
1. Start from the production branch
g co production
2. Pull any new changes residing on production
g pull
3. Create your feature branch
g co -b fix-002
4. Create an empty commit, push the branch, submit a pull request
g commit --allow-empty -m "First Commit"
g push -u origin fix-002
g pr
5. Commit locally
When you’ve written some awesome code!
g add .
g commit
And add a minimally-meaningful commit message. These will end up squashed in step 6.
Optional 5a. Giddy up!
g up
6. Rebase with production
When your feature is done and ready for deployment! When we rebase and squash
commits, we like to write meaningful commit messages and as a final line, we’ll
include: Fixes #2. GitHub picks up on this and automatically closes the issues
when this commit is merged to production.
g ir
7. Locally merge fix-002 on production
g co production
g pull
g merge fix-002
8. Push to production
g push
9. Delete your branch both locally and on GitHub
g rmb fix-002
Aliases and shortcuts used above
In ~/.gitconfig add:
[alias]
co = checkout
up = !git fetch origin && git rebase origin/$DEFAULT_BRANCH
ir = !git rebase -i origin/$DEFAULT_BRANCH
pr = pull-request
rmb = !sh -c 'git branch -d $1 && git push origin :$1' -
In ~/.bash_profile (or equivalent) add:
alias g=git
Footnotes
Step 1: We’ve opted to use a branch called production instead of
git’s default, master. This decision was made because “production” seems to
convey the purpose/destiantion of the branch more fully and “master”, as a
word, has problematic baggage.
Step 4: This is optional and not everybody on the team opens an empty
pull request. You’re welcome to skip this step and run
g push -u origin fix-002; g pr making your first meaningful commit.
Step 4, on awesomeness: Doesn’t have to be awesome. Most code isn’t awesome.
Step 5a: “Giddy up” is what I affectionately call the process of
updating your local branch with whatever fabulous code has been committed to
production in the meantime.
Step 6: This is the part where we squash all of our commits down to 1 per issue resolved.
Step 9: This is a cool alias that deletes your local and remote (GitHub) branches. Don’t worry, it’ll yell at you if you have unmerged code!